
PEERS Data Hub webinar
Statewide Longitudinal Data Systems: What constitutes the Michigan Education Data Center and how can it be used to further STEM education research?
Watch the video or View the slide deck
Data Overview
Data held by the Michigan Education Data Center cover numerous topics of interest to education researchers. From early childhood through postsecondary and from individual-level to district-level data, many of these elements can be joined to establish a powerful longitudinal view of Michigan's education context. More about the data
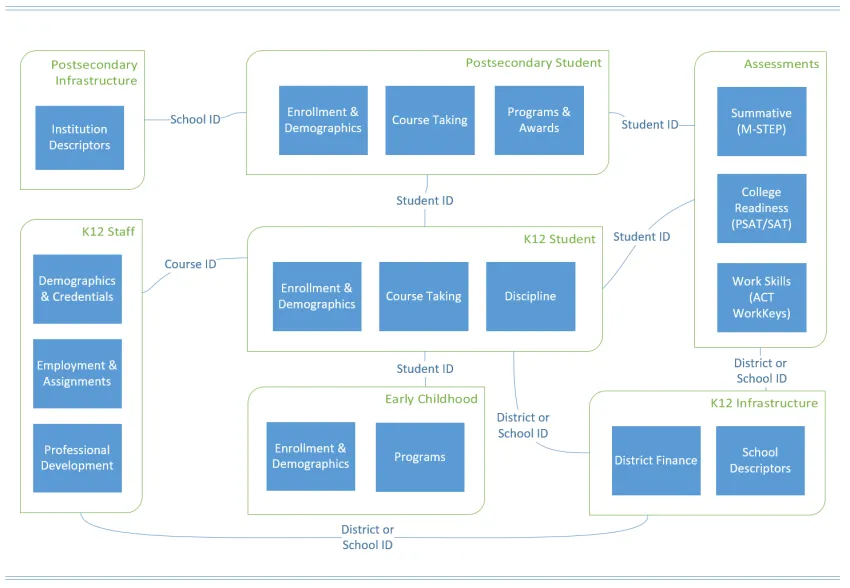
Record Matching
Individual student records within educational datasets maintained by MEDC are labeled with a unique identifier, generated by the State of Michigan, which allows researchers looking to perform analysis across multiple datasets to be fairly certain which records correspond to the same individual. However, this limits the scope of any analysis to these internal datasets and the variables they contain. In an instance where a researcher has access to an external dataset, they would be unable to investigate any relations between that dataset and MEDC’s data.
In addition to educational research datasets, MEDC also maintains a dataset containing the personally identifiable information (PII) of a large proportion of Michigan’s K-12 student population, including full names, dates of birth, racial/ethnic status, and addresses, each of which is associated with the state’s unique identifier. With this dataset, MEDC has developed a probabilistic matching model that allows it to match MEDC data with external data in cases where the external data each dataset contains at least some personally identifiable information in common.
The following is an overview of the process by which MEDC performs a probabilistic match between any incoming dataset and the PII dataset maintained in house. We provide a broad overview of some of the major concepts relevant to record linkage, including data cleaning, blocking, performing field and record level comparisons, and evaluation metrics and techniques. Read more about the MEDC matching process (PDF).
Data Security Guidelines
Data made available through the Michigan Education Research Institute describe Michigan's children. It is critical that researchers keep data security at the forefront during every stage. Before submitting a research application, researchers should review these guidelines and work with their institution's IT and data security experts to make sure best practices are followed.
- In most cases, the use of cloud storage (e.g., Box, Dropbox) or work computers will not be approved for data storage. Talk with your institution's IT staff and ask for secured network storage.
- Data must be stored within the United States.
- Describe how account management will be used to ensure only approved users have access to the data. Group-based policies (vs. allowing access on a one-off basis) are preferred. Your institution should have a role in issuing accounts that requires personal information (e.g., date of birth, address) to confirm the identity.
- How often will data access be reviewed and updated?
- Describe how you plan to access and analyze the data. We recommend only using "work" computers or remote desktops that are monitored by your institution's IT staff.
- How will you access data from off-campus? Whatever the answer, it should include the use of a VPN or other means to ensure end-to-end encryption of data.
The following is an example of data security verbiage describing the infrastructure used by the Michigan Education Data Center and affiliated researchers at the University of Michigan.
Sensitive data housed by MEDC reside solely on file, database or computational servers hosted within U-M data centers in Washtenaw County, MI. These servers are highly secure and approved for use with FERPA, Export Controlled (ITAR, EAR), PII, HIPAA and Sensitive Human Subject Research data. All servers are monitored 24/7 for network and physical intrusion and regularly patched by U-M Information Technology Services. Group-based access controls ensure data access follows the principle of least privilege. Separate server instances are used to ensure identifiable and de-identified data are not co-mingled. Virtual data enclaves requiring a VPN connection and two-factor authentication allow approved researchers to analyze data without removing it from protected data centers.
Data Delivery Schedule
MEDC generally receives data for the most recently completed academic year 6-12 months after completion of the academic year. The schedule below shows roughly when we expect data from the preceding academic year to arrive.
Topic | Dataset | Start Year | Estimated Arrival |
|---|---|---|---|
Early Learning | Early On Program Eligibility and Enrollment | 2013 | Aug |
Early Learning | Early Childhood Demographics and Program Enrollment | 2012 | Oct |
K12 Student | K-12 Student Demographic and Enrollment Data | 2003 | Aug |
K12 Student | K12 Graduation | 2007 | Mar |
K12 Student | K-12 Student Coursework | 2011 | Oct |
K12 Student | K-12 Student Infractions and Discipline | 2011 | Aug |
Assessment | K-12 Student Assessments | 2008 | Nov |
Assessment | K-12 Student Assessments - Accommodations | 2008 | Nov |
Assessment | K-12 Student Assessments - English Language Learner | 2008 | Nov |
Assessment | K-12 Student Assessments - Career and College Readiness | 2008 | Nov |
Infrastructure | K-12 District Finance | 2004 | Jul |
Infrastructure | K-12 Educational Institutions | 2006 | Aug |
Infrastructure | Postsecondary Educational Institutions | 2008 | Oct |
Staff | K-12 Staff Demographic, Employment and Assignment Data | 2004 | Sep |
Staff | K-12 Staff Education and Certification (Endorsements) | 2012 | Sep |
Staff | K-12 Staff Education and Certification (Professional Development) | 2004 | Jan |
Staff | K-12 Staff Education and Certification (Michigan Test for Teacher Certification) | 1992 | Nov |
Postsecondary | Postsecondary Student | 2010 | Feb |
Postsecondary | Postsecondary Student Awards | 2010 | Feb |
Postsecondary | Postsecondary Student Coursework | 2010 | Feb |